

 アクセス
アクセス サイトマップ
サイトマップ深層ニューラルネットワークを用いた人物動作生成モデルの構築
3DCGを用いた映画やゲームにおけるキャラクタアニメーションの制作を容易にするための研究を行っています.
人物動作生成モデルとは
映画やゲームといった3次元コンピュータグラフィックスのコンテンツには人型のキャラクタが登場することが多く,キャラクタの動作を生成・制御・編集することは重要なタスクです.私たちは,モーションキャプチャシステムにより収録された人間の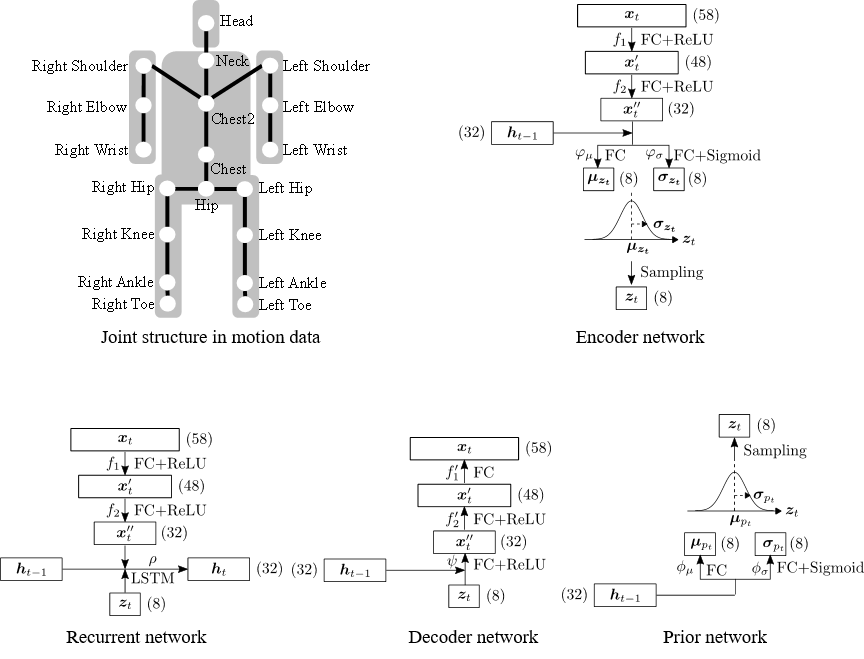
動作データから学習することで,多様で自然な動作を生成することができるモデルを構築し,このモデルによりキャラクタアニメーションの制作を容易にしようとしています.
深層生成モデルによる動作生成例
私たちは,深層ニューラルネットワークを使用した生成モデルであるVariational Autoencoderと動作における時間方向の関係性を表現することができるLSTM-RNNを組み合わせたモデルを構築しました.構築した深層生成モデルを使用すると多様で自然な動作データが生成できることを確認しています.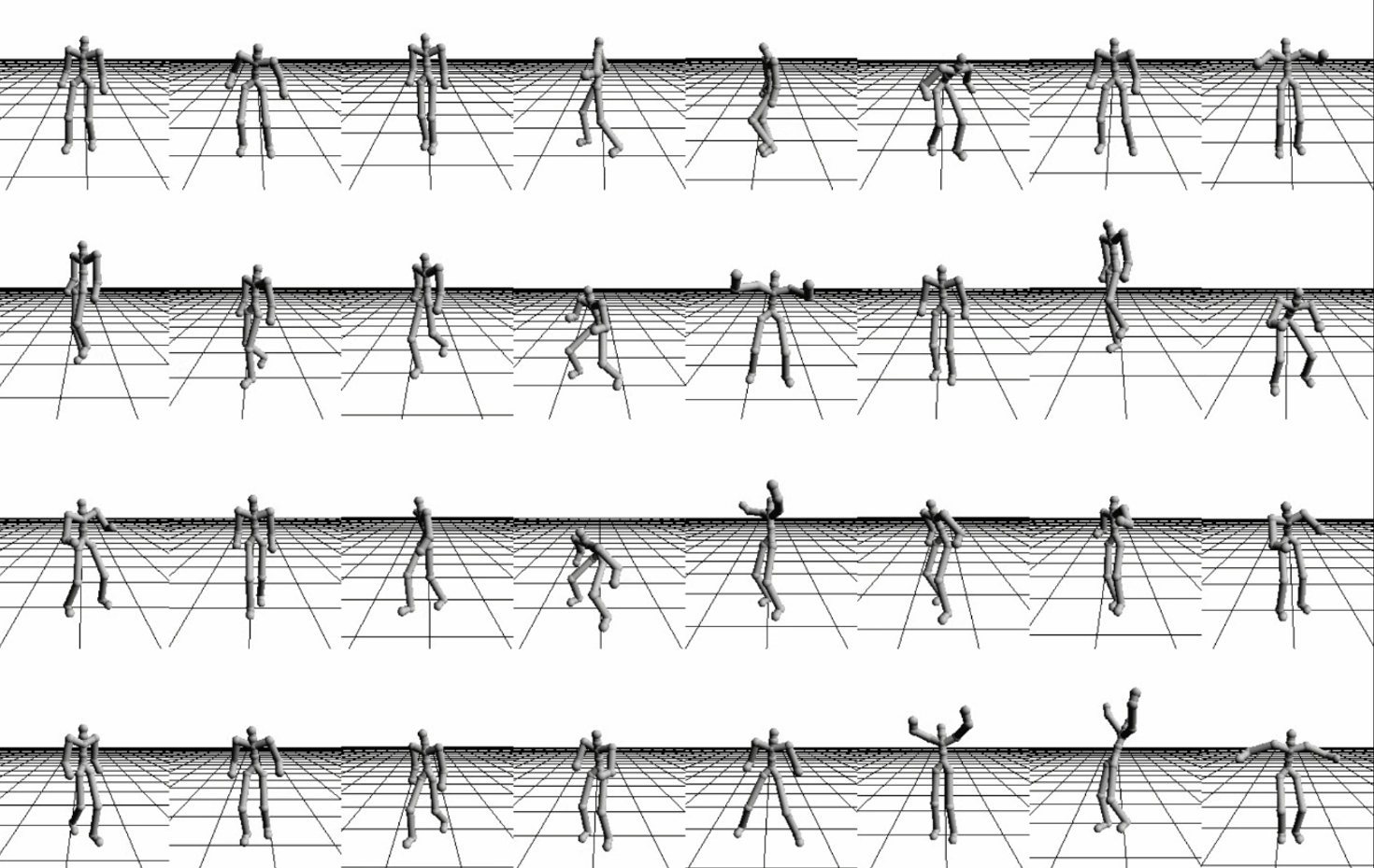
深層ニューラルネットワークを用いたシーンラベリングに適した訓練データの生成
深層ニューラルネットワークによる画像認識の問題を解決するための研究を行っています.
ニューラルネットワークを用いたシーンラベリングの課題
シーンラベリングとは画像認識のタスクの1つで,様々な物体が写っている画像を入力すると,各画素にクラスラベルを出力するタスクです.深層ニューラルネットワークを用いてシーンラベリングを行っている研究では,訓練データにあまり含まれないクラスに対する正解率が低くなる傾向があります.正解率を向上させるには,各クラスの訓練データのバリエーションを増やすことと,クラスごとの訓練データの頻度の差をなくすことが必要になります.しかし,シーンラベリングで使用される訓練データは各画素に正解クラスラベルが付与されたデータであるため,訓練データを作るには膨大な手間がかかります.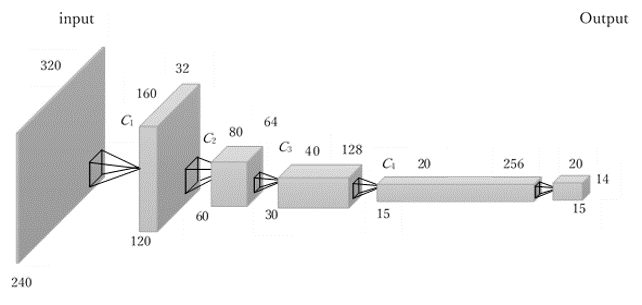
SceneNetを使用した訓練データの生成
私たちは,3次元コンピュータグラフィックスで合成したクラスラベル付き画像を訓練データとすることで,この問題を解決しようとしています.SceneNet[1]により生成したデータを用いて訓練とテストを繰り返し,正解率の低いクラスオブジェクトの出現確率を上げて訓練データを生成し学習した結果,正解率が向上することを確認しています.
[1] J. McCormac, et al., "SceneNet RGB-D: 5M Photorealistic Images of Synthetic Indoor Trajectories with Ground Truth", ICCV2017.
ARキャラクタによる対話システムの構築
人と共に暮らし,人と会話ができる擬人化エージェントシステムを構築しています.
ARキャラクタによる対話システムとは
私たちは,家庭や屋外といった人が暮らす現実の環境で人と会話することができるシステムの構築を目指し,拡張現実(Augmented Reality: AR)技術を使用したARキャラクタによる対話システムを提案しています.提案システムでは,ユーザは頭部にヘッドマウントディスプレイ・カメラ・マイク・イヤフォンを装着します.まず,カメラから得られた映像をヘッドマウントディスプレイに表示し,AR技術を使用して人型のCGキャラクタをヘッドマウントディスプレイに表示されている映像中に合成表示します.また,マイクとイヤフォンによりユーザはARキャラクタと会話することができます.
ARキャラクタ対話システムの実行例
実装したシステムでは,ヘッドマウントディスプレイに方向を推定できるセンサが搭載されていて,センサから得られるユーザの顔の向きに応じてARキャラクタを適切な位置に表示するようにしています.また,カメラには距離データを取得できるセンサが搭載されていて,現実世界のオブジェクトとARキャラクタの前後関係を判定し,オブジェクトの後ろにARキャラクタが隠れるように表示することも可能となっています.
ARキャラクタの動作制御部の構築
被験者に隠れてARキャラクタを操作できるAR WoZシステムを構築し,ARキャラクタの動作制御部を構築しようとしています.
AR WoZシステムとは
ARキャラクタをどのように動作させればよいかは,システムの目的や状況に応じて異なります.Human Robot Interaction研究では,人間が被験者に隠れてロボットを操作するWizard of Oz(WoZ)法によりロボットと被験者のやり取りのデータを取得し,それらを分析することで状況やタスクに適したロボットの動作を明らかにし,それを元にロボットの動作を制御するという方法が用いられています.私たちも,人間が被験者に隠れ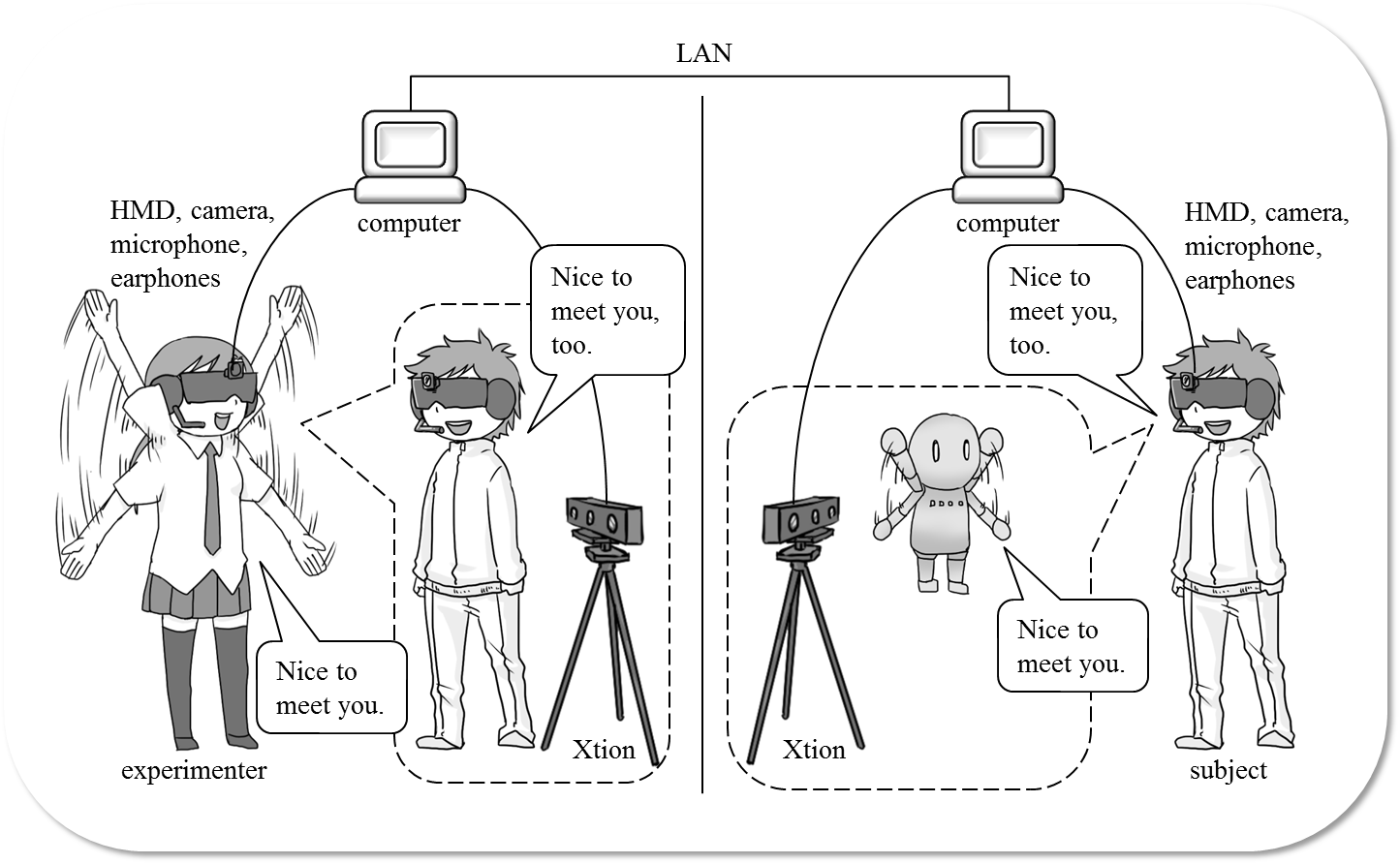

てARキャラクタを操作できるAR WoZシステムを構築し,このシステムを用いて様々な状況で被験者実験を行い,ARキャラクタの動作制御部を構築しようとしています.
対話に適したユーザとARキャラクタの位置関係の分析
私たちは,ARキャラクタの動作制御部構築の第一段階として,何も置かれていない机に向かって椅子に腰かけた状態のユーザが机の上に立っているARキャラクタと対話する際の最適な位置関係の分析を行っています.
ARキャラクタによる道案内システムの構築
人が人を道案内するように,楽しく会話をしながら歩いていたら,いつの間にか目的地に着いていたと思えるような道案内システムを構築しようとしています.
ARキャラクタによる道案内システムとは
現在,スマートフォンや携帯電話で使用できる地図アプリには,ナビゲーション機能が搭載さているものが多く,それらは地図上に現在地と目的地までのルートを表示することで,ユーザを目的地まで誘導します.また,スマートフォンや携帯電話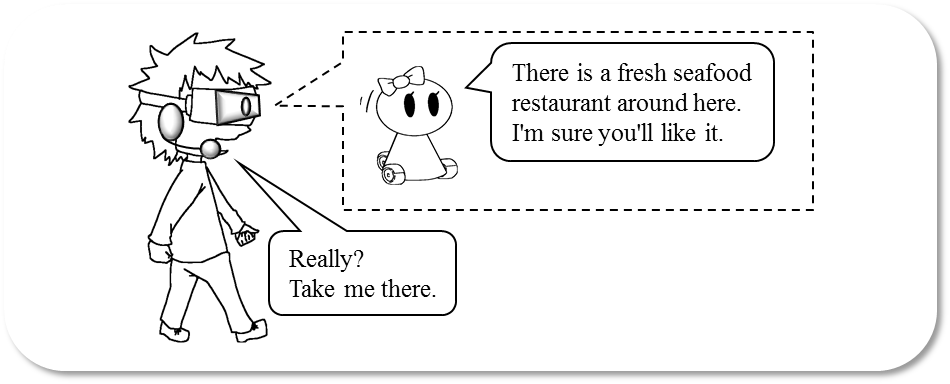
にはカメラが搭載されているものが多く,地図上にルートを表示する代わりに,カメラから得られた現実の映像中にAR技術を使用して矢印等を表示するシステムもあります.私たちは,現実の映像中に人型のキャラクタを表示させ,そのキャラクタが道案内をしてくれるARキャラクタによる道案内システムを構築しようとしています.
人間同士の道案内における位置関係の分析
人が人を道案内する場合,ただ先導したり口頭で指示を出したりすることはあまりなく,目的地やその土地に関する話をしながら並んで歩くことが多く,案内される人にとっては話をしていたらいつの間にか目的地に着いていたと感じることもあります.私たちは,ARキャラクタにこのような方法で道案内をさせることを目指し,被験者実験により人が人を道案内する際のお互いの位置データを計測し,人間がどのように道案内をしているのかを明らかにしようとしています.
共食コミュニケーション支援システムの構築
遠隔地にいる人同士が同じ食卓を囲んで食事をしながらコミュニケーションをとっていると感じられるシステムを構築しようとしています.
共食コミュニケーション支援システムとは
近年日本では,単身者・病院の入院患者・共働きの両親を持つ子供などが増加していて,孤食と呼ばれる1人で食事をする行為が増えています.そこで,私たちは,遠隔地にいる人同士が同じ食卓を囲んで食事をしながらコミュニケーションをとっていると感じられる共食コミュニケーション支援システムを構築しようとしています.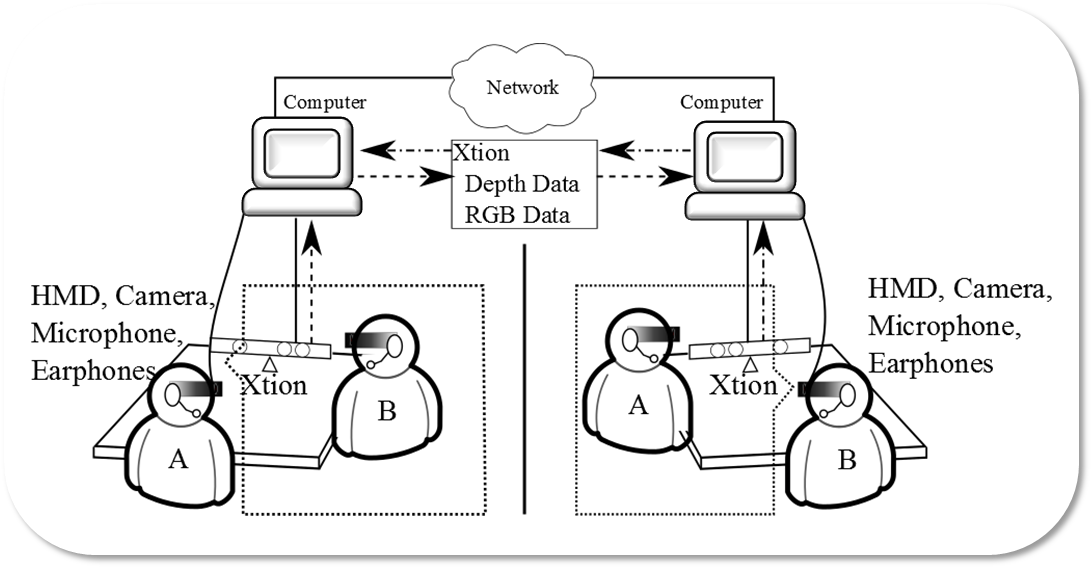
共食コミュニケーション支援システムの実装
複数人の会話では顔の向きや視線の情報が重要であるため,私たちは,顔の向きの情報を相互に送受信可能で,家庭や病室等で利用できる程度に小規模な遠隔コミュニケーションシステムを構築しました.具体的には,卓上に設置されたXtionセンサを用い,リアルタイムでユーザの上半身の3次元情報と色情報を取得し,ネットワークを介して送信します.受信側では,カメラとヘッドマウントディスプレイを頭部に装着したユーザに対して,カメラから得られた映像にAR技術を使用して受信した遠隔ユーザの3次元ポリゴンを合成し,ヘッドマウントディスプレイに表示します.このとき,ヘッドマウントディスプレイに搭載されたセンサによりユーザの顔の向きを推定し,顔の向きに応じて遠隔ユーザを適切な位置に表示させるようにしています.